
SAP programs rarely run into trouble because test cases are missing.
They stall because the right data does not exist when teams need it.
During S/4HANA migrations, rollouts, upgrades, or quarterly release cycles, the same pattern appears again and again. Key master records are not there. Transactions cannot be completed end to end. Finance balances do not reconcile. Automation scripts fail after refreshes. Masked production copies break business logic. Environments drift out of sync.
That is why experienced SAP organizations treat test data creation as an engineering discipline, not a last-minute activity before UAT.
This article explains what kinds of data must be created for SAP testing, how requirements change across different test phases, which modules and objects are involved, how teams usually create and manage that data, and how mature programs avoid constant firefighting.
Why Test Data Planning Is So Critical in SAP
SAP landscapes are tightly coupled. A single sales scenario might rely on a business partner record, a material master, pricing conditions, tax codes, shipping points, credit management rules, and the correct G/L accounts in Finance. When even one of those objects is missing or inconsistent, the process collapses.
Now multiply that complexity across integration cycles, regression packs, migration mock runs, user acceptance testing, and CI-driven automation pipelines.
Without a structured test-data approach, teams fall back on unhealthy habits: recycling old documents, ordering repeated full system copies, masking sensitive fields too late, or manually fixing tables after every refresh. The result is frozen systems, delayed releases, and exhausted project teams.
How Test Data Requirements Change Across SAP Testing Phases
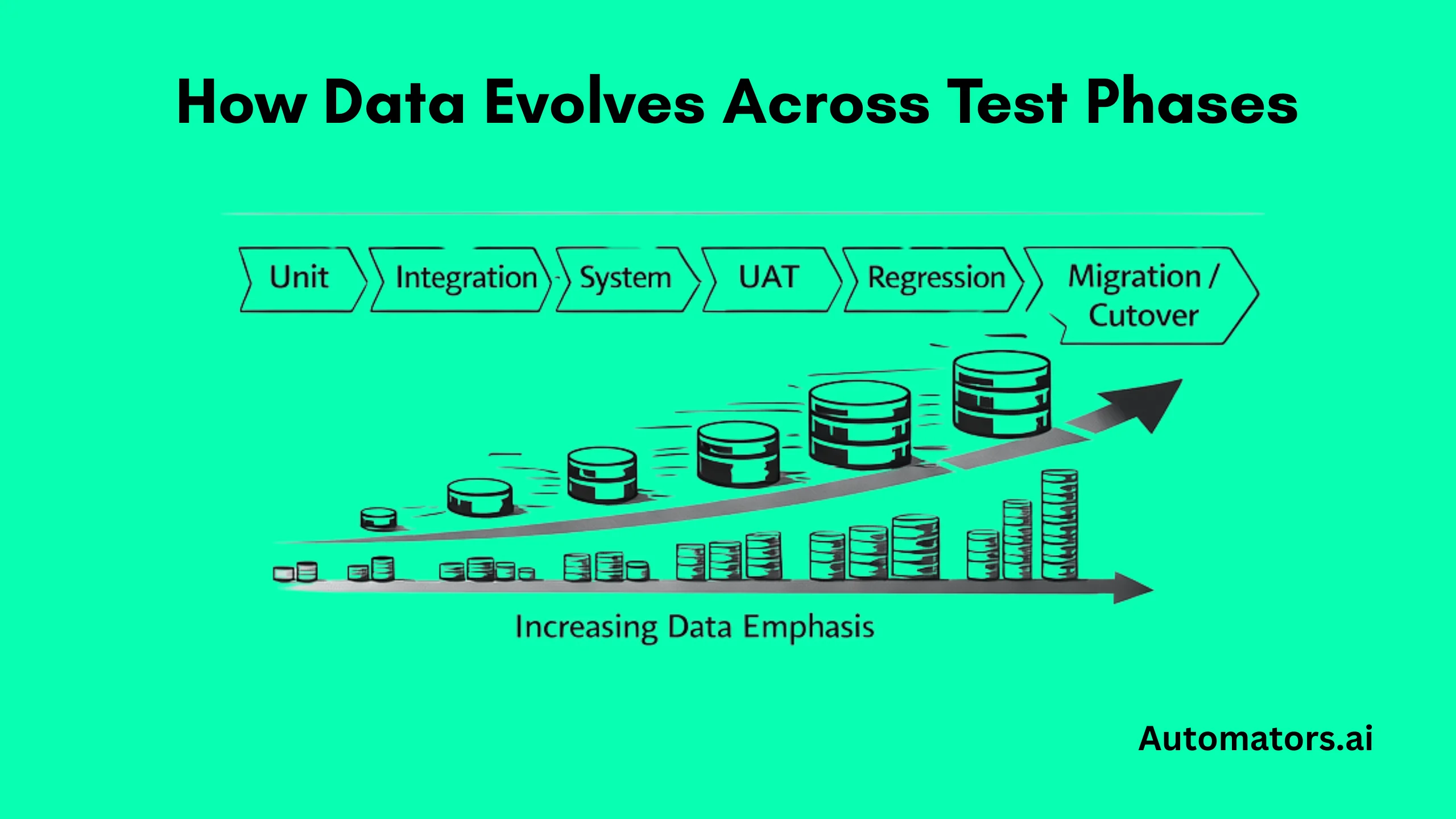
One of the biggest mistakes in SAP programs is assuming that the same dataset can serve every test stage. In reality, each phase demands very different kinds of data.
a. Unit Testing: Speed and Isolation
During unit testing, teams usually work with minimal records. A single company code, one customer or vendor, one material, and narrowly defined pricing or tax rules are often enough to verify custom code or configuration logic.
The goal here is not realism. It is fast feedback and tightly controlled scope.
b. Integration Testing: End-to-End Flows
Integration testing shifts the focus to cross-module processes. SD must post correctly into FI, procurement needs to generate accounting documents, and warehouse or transportation integrations have to run end to end.
That requires complete master-data hierarchies, organizational structures, posting rules, and settlement logic that reflect real business relationships rather than isolated test cases.
c. System Testing: Realistic Business Scenarios
System testing pushes realism further. Historical transactions, reversals, partial deliveries, blocked customers, credit limits, returns, and cancellations become essential because these are exactly the situations that surface subtle defects in configuration or custom code.
d. User Acceptance Testing (UAT): Production-Like Conditions
In UAT, business users expect data that looks and feels familiar. Teams typically load anonymized production-like datasets with realistic volumes and country-specific variations, while ensuring that personal or sensitive information is protected.
The objective is confidence. Business stakeholders must be able to validate that the system supports daily operations.
e. Regression and Automation Testing: Stability and Reset
Regression and automation testing demand something different again: stability. The same identifiers must exist across runs, and scenarios must be resettable between cycles.
“Golden datasets” are usually curated so scripts can execute repeatedly without being rebuilt after every refresh.
f. Performance and Volume Testing: Scale Under Pressure
Performance testing introduces scale. Here, teams generate millions of transactions, simulate peak posting periods, run mass-pricing updates, and stress batch jobs to see how the system behaves under load.
These datasets are less about functional correctness and more about throughput, timing, and system limits.
g. Migration and Cutover Testing: Data Integrity
Finally, migration and cutover testing focuses on data correctness after conversion. Migrated master records, open AR and AP items, asset balances, inventory stock, historical postings, and reconciliation datasets all become critical because they determine whether the business can legally and operationally go live.
The Core Categories of Data SAP Projects Must Create
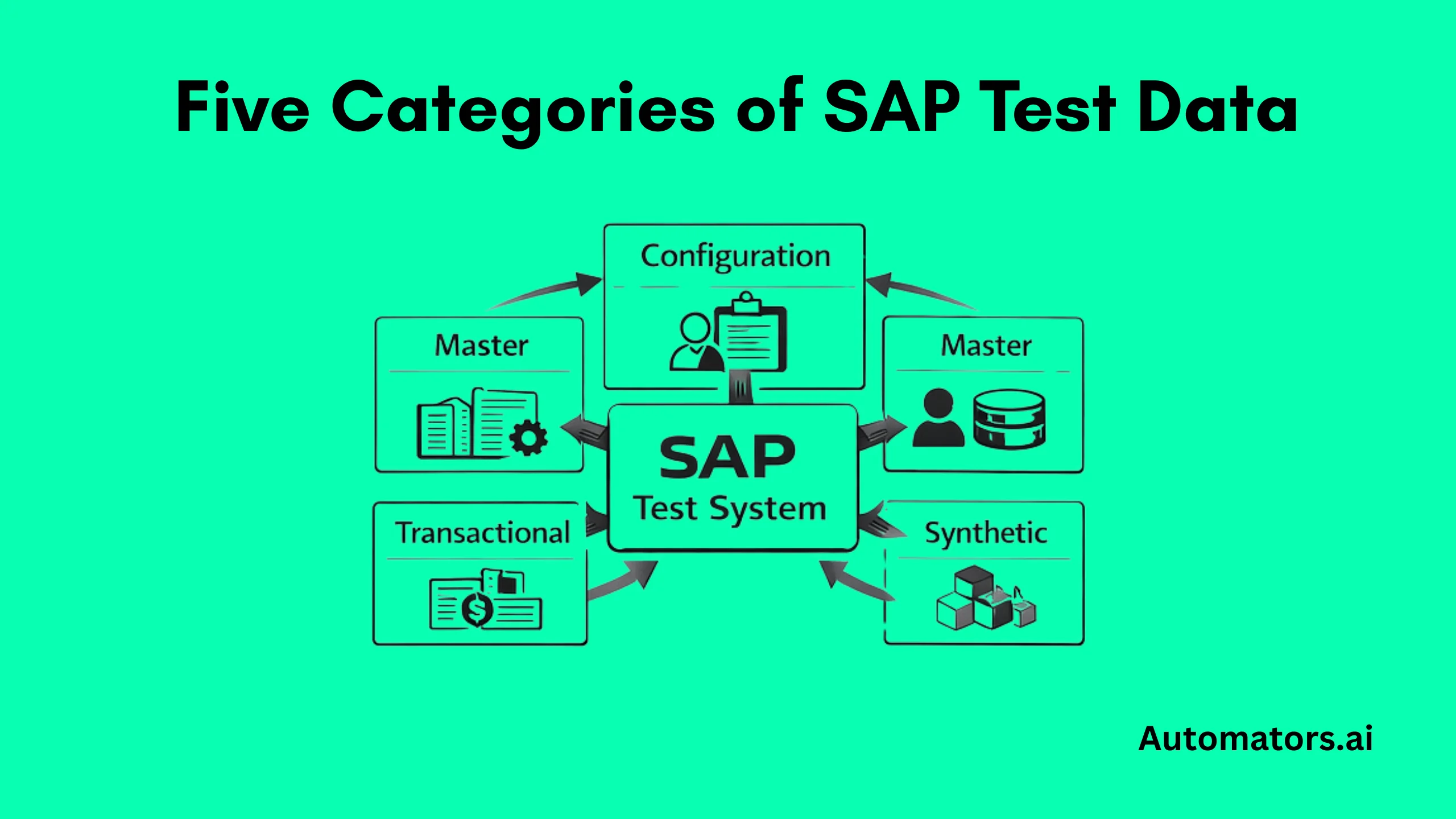
Across all testing phases, SAP programs usually rely on five broad categories of data. Each plays a different role in keeping scenarios executable, automation stable, and finance results defensible.
a. Configuration Data
Configuration data defines how the system behaves. It includes organizational structures, account-determination logic, pricing procedures, tax rules, output control, and MRP parameters.
Even perfectly created master data will fail if it does not align with customizing. In practice, many test defects traced to “bad data” actually originate from configuration that no longer matches the scenarios being exercised.
b. Master Data
Master data forms the foundation for nearly every SAP process. Business partners, customers, vendors, materials, plants, profit centers, cost centers, charts of accounts, pricing conditions, and credit segments all live here.
For testing, these objects rarely exist in just one form. Teams normally need blocked and released variants, domestic and foreign customers, multiple account groups, and deliberately awkward edge cases that expose error handling.
c. Transactional Data
Transactional data represents business activity itself. Sales orders, deliveries, billing documents, purchase orders, goods movements, production orders, FI postings, asset acquisitions, and intercompany invoices all fall into this category.
Good transactional test data must link cleanly to master records and cover not only happy paths but also reversals, partial processes, cancellations, and posting failures that mirror real-world operations.
d. Financial and Historical Data
Financial balances and historical records deserve special treatment. Opening balances, inventory valuation, asset values, work in progress, accruals, provisions, and open AR or AP items are indispensable during cutover rehearsals, year-end close testing, and audit simulations.
Without these datasets, finance teams cannot realistically validate closing activities or regulatory reporting in test systems.
e. Synthetic or Test-Specific Data
Synthetic data fills the gaps that production rarely covers. Extreme pricing combinations, rare tax rules, massive volume scenarios, negative test cases, and privacy-safe personal records often have to be generated artificially so compliance requirements are respected while coverage remains high.
To make these categories easier to compare at a glance, the table below summarizes how SAP teams typically think about each type of test data.
| Data Category | What It Covers | Typical SAP Examples | Why It Is Created |
| Configuration Data | System settings and business rules | Pricing procedures, tax rules, account determination, MRP parameters | Enables transactions to post correctly and reflect real processes |
| Master Data | Core business objects reused across processes | Business partners, materials, plants, profit centers, charts of accounts | Forms the foundation for all testing and must exist in multiple variants |
| Transactional Data | Day-to-day business documents | Sales orders, billing documents, purchase orders, FI postings | Validates end-to-end scenarios and error handling |
| Financial Balances and History | Open items and historical financial state | AR/AP balances, asset values, inventory stock | Required for cutover rehearsals, audits, and close testing |
| Synthetic or Test-Specific Data | Artificially generated edge cases and volumes | Rare tax setups, extreme pricing, stress records | Covers scenarios production data cannot provide safely |
Which SAP Modules Are Usually Involved
SAP test data almost never sits inside a single module. Finance requires company codes, G/L accounts, and open items. Sales depends on customers, sales areas, and billing data. Procurement needs materials, vendors, and purchase orders.
Manufacturing relies on BOMs, routings, and production orders. Logistics introduces plants, storage locations, and deliveries. HR or HCM brings employees and payroll structures into the picture.
Realistic testing only works when these objects line up across modules rather than being created in isolation.
How SAP Teams Actually Create Test Data
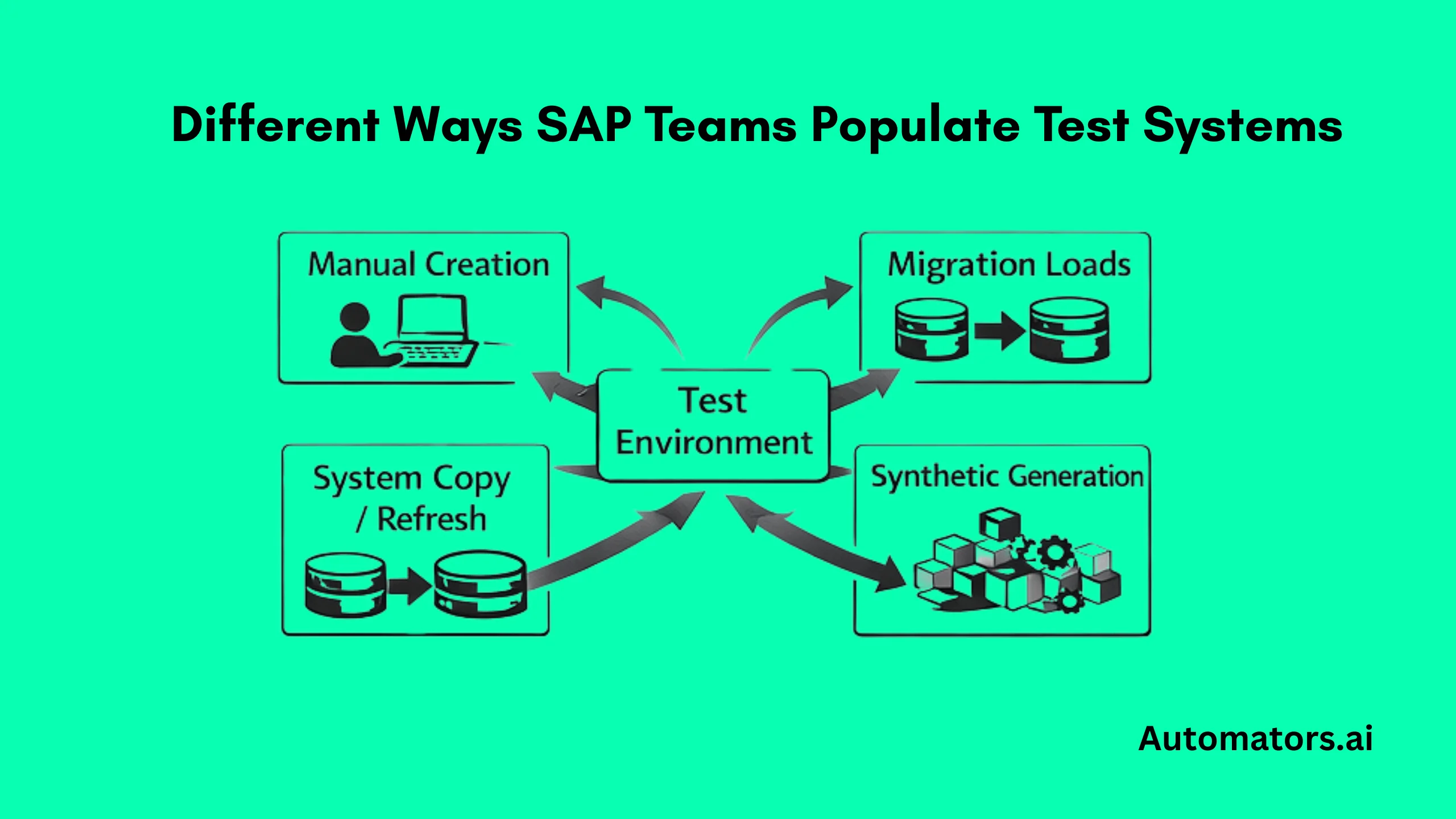
In practice, SAP projects rarely rely on a single technique. Most landscapes evolve toward a mix of manual creation, bulk loading, system copies, subsetting tools, and synthetic generation as test cycles become more frequent and automation grows.
a. Manual Creation Through SAP Transactions
Manual setup through standard SAP transactions is common in early project phases or for quick fixes. Consultants create customers, vendors, materials, and test orders directly in the system to validate configuration or custom logic.
This approach works when scope is small, but it does not scale once regression packs expand or multiple cycles run each week. Rebuilding the same datasets repeatedly becomes expensive and error-prone.
b. Bulk Loading and Migration Utilities
Migration and load tools are often used to seed systems in bulk at the start of a project, particularly during S/4 conversions or landscape builds. They are effective for initial population, especially when bringing large master-data sets into new environments.
Where they struggle is in repeated resets. Running these utilities before every regression or UAT cycle quickly becomes heavy, slow, and difficult to coordinate with changing test scopes.
c. System Copies and Selective Refreshes
System copies and targeted refreshes remain popular because they bring realistic structures and relationships from production into test systems.
At the same time, they introduce familiar side effects: downtime during refresh windows, long masking cycles, broken automation scripts, and gradual data drift between landscapes as each environment evolves differently.
These issues are rarely caused by tooling alone. They usually stem from how data is provisioned into SAP environments, how often refreshes occur, and whether scenarios can be rebuilt automatically afterward. We explore those mechanics and failure patterns in more detail in our SAP Test Data Provisioning* guide*.
d. Test Data Management and Subsetting Tools
To reduce the operational burden of full copies, many organizations introduce test-data-management or subsetting tools. These platforms carve out smaller, compliant slices of production while preserving relationships between objects across modules.
When implemented well, they shorten refresh cycles and improve governance, although they still depend on strong rules around ownership, masking, and refresh cadence.
e. Synthetic Data Generation for Repeatability
Synthetic data generation complements all of these techniques rather than replacing them outright. It is particularly useful for rebuilding scenarios after refreshes, preparing automation-friendly datasets, creating rare edge cases, seeding migration cycles, and generating the volumes needed for performance testing.
This is typically where platforms like Automators’ DataMaker are positioned, not as a replacement for SAP utilities, but as a way to make test data repeatable and controllable across delivery cycles.
The Problems SAP Teams Keep Running Into
Despite good intentions, the same difficulties appear in most large programs. Master data drifts between systems. Document chains break.
Privacy rules restrict the reuse of production data. Refresh cycles take too long. Automation becomes brittle. Manual repairs consume days of effort. Nobody quite owns the test-data domain.
These are not tooling problems alone. They are governance and process problems, and they explain why experienced organizations formalize test-data strategies early rather than reacting late.
What Mature SAP Programs Do Differently
More advanced teams stop treating test data as a side activity and build it into their delivery model. They combine baseline system copies with selective refreshes, curate stable regression datasets, automate provisioning, generate synthetic scenarios where production cannot help, and trigger resets through CI pipelines.
At that point, test data becomes part of the engineering architecture rather than operational plumbing.
A Practical Readiness Check Before UAT or Regression
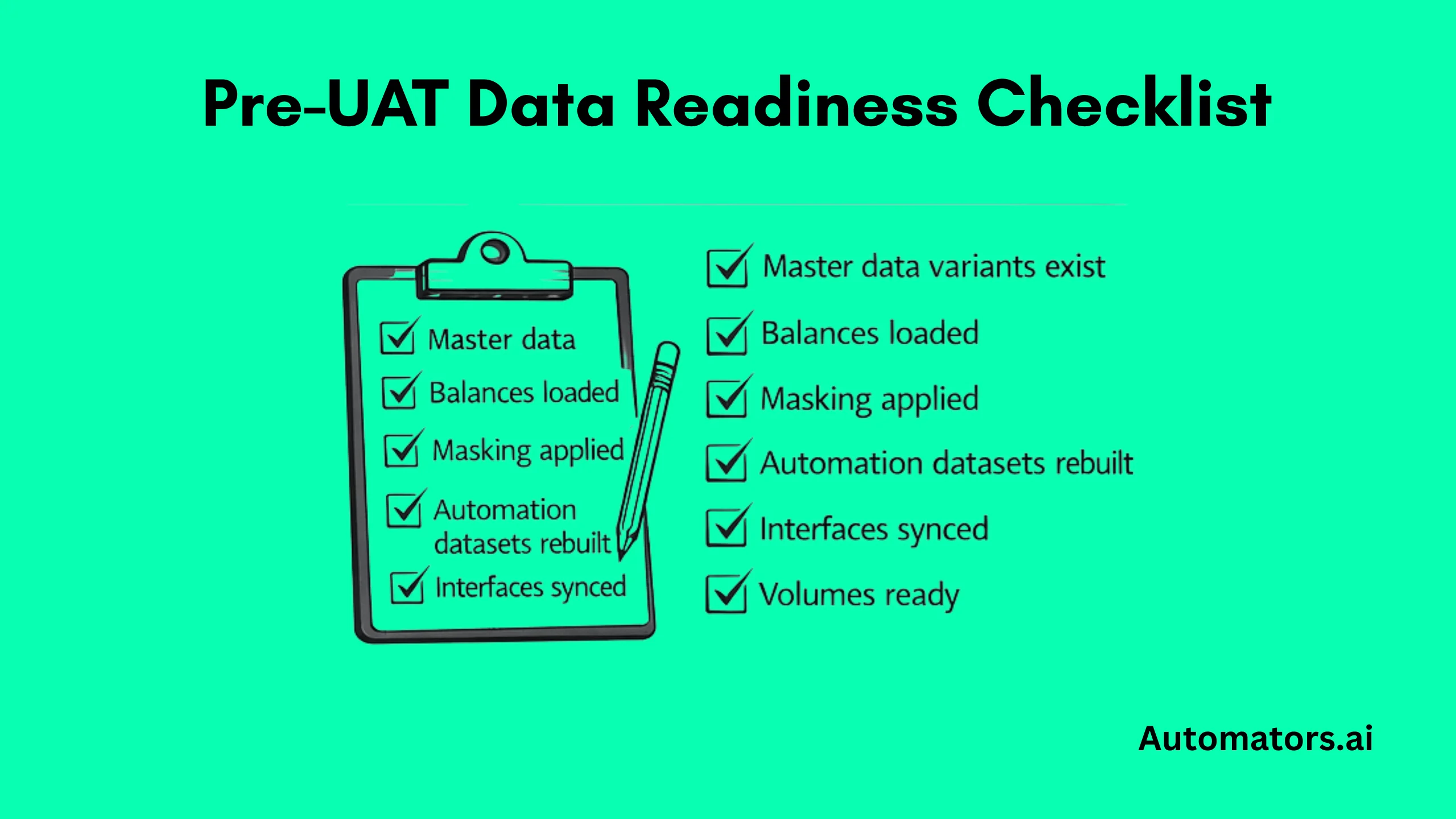
Before major test cycles begin, experienced SAP teams quietly confirm a few fundamentals. Skipping any of these usually means defects later get blamed on test cases when the real cause is missing or unstable data.
- business partners exist in every required region
- blocked and released variants are available
- pricing and tax rules match customizing
- open AR and AP items are present
- inventory balances reconcile
- automation datasets can be reset
- sensitive fields are anonymized
- migration reconciliation sets are ready
- performance volumes have been prepared
Catching gaps in these areas early almost always saves weeks later in the program.
Final Thoughts
In SAP programs, testing becomes predictable only when test data is engineered deliberately.
Teams that depend on repeated system copies, recycled documents, or last-minute fixes before UAT usually end up with unstable automation, slow migration cycles, and stalled releases.
Mature programs take a different path. They define which objects must exist, how datasets change by test phase, how environments are refreshed, and who owns the data. They treat test data preparation as core delivery infrastructure, not background work.
That discipline shows up quickly in results: regression packs stabilize, migration rehearsals accelerate, finance teams can close with confidence, and compliance stops blocking releases late.
The takeaway is simple. SAP testing does not fail because of test cases. It fails because test data was never engineered properly.