
Reliable SAP test data is one of the hardest parts of SAP quality assurance.
Between strict compliance rules, interconnected business modules, and complex end-to-end processes, testing often slows down simply because teams do not have the right data at the right time.
That is why SAP QA teams are shifting toward test data generators, tools that help create safe, realistic, and reusable SAP test data without copying production information.
In this guide, we'll explore the top test data generators available in the market so that you can tackle all your test data needs with ease.
We'll start with native SAP options, highlighting their pros and cons, and then, we'll cover leading third-party tools as well, so that you can choose a solution based on your specific scenarios.
A. Native SAP Test Data Solutions
While SAP does not offer a dedicated test data generator, it does provide several built-in tools and features that help teams prepare or load data into non-production environments.
Some support client copies, some support automated data entry, and some assist developers with AI-powered code and content generation.
The table below summarizes the most relevant SAP-native options that QA teams often rely on during test data preparation.
| Tool | What It Does | Best For | Pros | Limitations |
| SAP TDMS (Test Data Migration Server) | Copies and scrambles selected production data into QA systems | Creating lean, realistic QA clients without full system copies | Reduces dataset size. Maintains business context. SAP-supported. | No synthetic data creation. Complex setup. |
| SAP Client Copy (SCCL / SCC9) | Creates new clients or refreshes existing ones using local or remote copies | Initializing QA, sandbox, or training systems | Simple. Standard utility in all SAP systems. | Heavy, slow, and requires masking outside SAP. |
| LSMW / LTMC | Loads master and transactional data from templates into SAP | Targeted datasets needed for specific test scenarios | Flexible. Template-based and repeatable. | Manual prep required. Limited volume. |
| SAP Script Recording & Playback | Records and replays SAP GUI actions that create or update data | Small recurring tasks or quick one-off data creation | Easy to record. Helps when no automation tool is available. | Not stable for complex processes. Limited validation. |
| SAP HANA Generative AI | AI-assisted content generation, code suggestions, and natural-language querying inside SAP HANA. | Developer productivity, query generation, and documentation tasks. | Helpful for development teams. Integrates with SAP HANA Cloud (can generate synthetic test data). | Primarily for code/dev tasks, not optimized for full-scale SAP test datasets or business process data (risk of inaccuracies in generated data). |
Summary
As you can see, these native tools are useful for basic usage, initial system setup, or small testing needs. But they have limitations for large-scale, accurate, or reusable test data preparation, which often leads to inconsistent environments and compliance challenges.
Before Moving to Third-Party Tools… Ask Yourself This
“Are these tools enough for your specific SAP testing needs?”
Use the decision guide below to find out.
Should You Stick With SAP Native Tools? (Decision Guide)
| Situation | Best Native Tool(s) | Why Native Tools Are Enough |
| You need an initial system setup or refresh | Client Copy (SCCL/SCC9), TDMS | Ideal for creating baseline QA, sandbox, or training clients with production-aligned data. |
| Testing is low-volume or occasional | Script Recording & Playback, LSMW, LTMC | Works for small datasets, simple uploads, or quick one-off data creation. |
| Production-aligned data is acceptable | TDMS, Client Copy, LTMC | Masked or copied data is sufficient for basic functional testing. |
| Testing is mostly manual | SAP Script Recording & Playback | No need for dynamic or frequent data generation. |
| You need help with SQL, queries, documentation, or content assistance—not data generation | SAP HANA Generative AI | Useful when teams need AI-powered developer support rather than creating test data itself. |
| Compliance can be handled via masking rather than synthetic data | TDMS (and partner masking tools) | Ensures non-sensitive, production-based data without synthetic generation. |
Native SAP tools work well when your testing relies on production-aligned data, small datasets, or manual workflows. Tools like TDMS, Client Copy, and template uploads are reliable for these cases.
However, if your testing needs go beyond small datasets, manual workflows, or production-aligned copies, you will quickly reach the limits of native SAP tools. Automated testing, CI/CD pipelines, and compliance-driven scenarios all require fresh and repeatable data that SAP does not generate on its own.
This is where third-party solutions become essential. The tools below are designed specifically to create or provision high-quality SAP test data at scale.
B. Third-Party Test Data Generators for SAP Testing
1. DataMaker
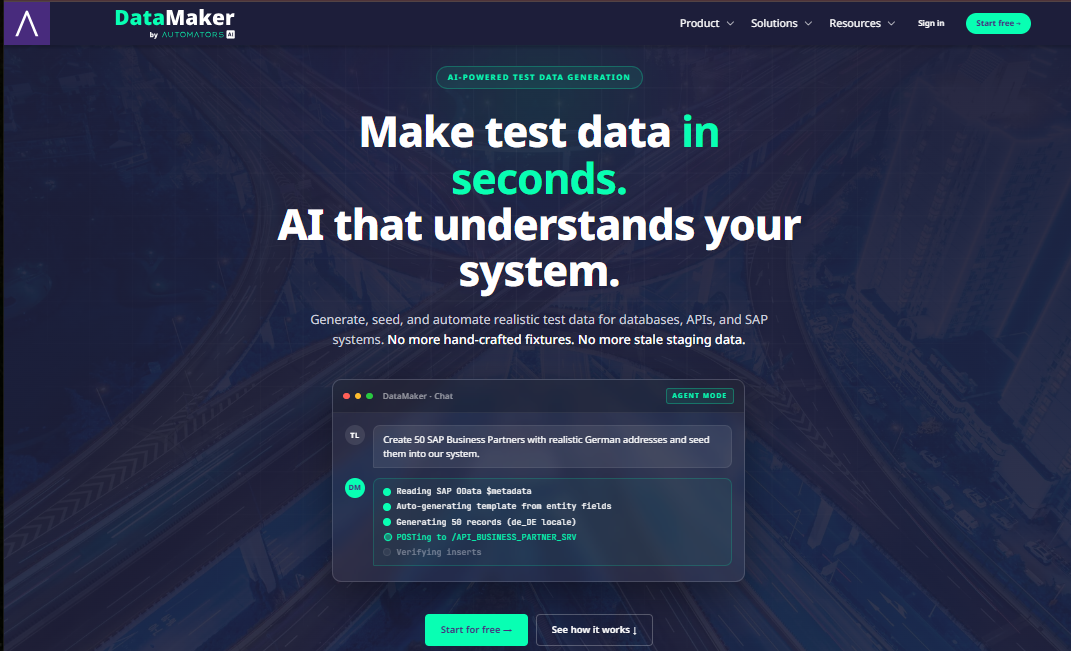
Automators DataMaker is an AI-assisted test data platform built for QA teams that need to generate, retrieve, and deliver safe, realistic, and repeatable SAP test data, without relying on production copies. It connects to SAP through standard OData services and supports metadata discovery, filtered retrieval, and write flows. SAP-specific mechanics like CSRF tokens are handled automatically.
One of its biggest advantages is the growing library of predefined templates for common SAP business objects such as Business Partner, Sales Order, and Purchase Requisition. These templates help teams create production-like data quickly, which is especially useful for automation scripts, regression packs, CI/CD pipelines, and cross-module SAP scenarios.
Beyond template-based generation, DataMaker provides an AI-assisted workspace with two modes. There's a conversational Chat mode for quick iteration, and a goal-driven Task mode for multi-step work that runs on a real worker pool.
Users can upload images, PDFs, JSON files, single CSVs, or whole CSV folders, and the AI will analyse them, infer structure, and auto-build reusable templates and scenarios. The same workspace also lets teams pull real records from SAP using natural-language filters, then save the result as a regression set. That workflow places DataMaker in the test data management space, not just synthetic generation.
The platform is designed to support modern testing environments where teams need repeatable data generation that integrates with automation frameworks, CI/CD pipelines, and AI coding assistants, all while maintaining strict data privacy standards.
The tool is also featured on SAP's official website through CNT Management Consulting AG, one of SAP's long-standing partners. This inclusion is supported by Andreas Dörner, a CNT partner who also sits on Automators' board, reinforcing the tool's credibility and alignment with SAP consulting best practices.
Top 7 Features That Make DataMaker Stand Out
a. Native SAP OData Integration (Read and Write)
DataMaker connects to SAP using standard OData services with three first-class capabilities. First, metadata discovery: the platform can read $metadata to understand entity structures. Second, filtered retrieval: pull real records like "German Business Partners created in the last 90 days" via OData GET. Third, direct write flows: post synthetic records into SAP via OData POST. CSRF tokens, authentication, and SAP-specific mechanics are handled automatically.
This dual read-write capability lets QA teams populate SAP systems with synthetic data and also build regression sets from real SAP records, both for processes such as O2C, P2P, and H2R, without production copies or manual imports.
b. Template-Based Data Modeling with Rich Expressiveness
DataMaker uses flexible templates to define fields, patterns, constraints, and relationships between datasets. Templates are not just flat field lists. They support nested objects and arrays, statistical distributions on individual fields, per-field Python scripts for custom logic, and AI-generated fields where the user describes what they want in plain English.
More than 50 built-in data types cover names, emails, IBANs, addresses, tax IDs, phone numbers, dates, and locale-aware variants. Once created, templates can be reused across automation workflows, regression suites, and CI/CD pipelines.
c. AI-Assisted Data Creation with Chat and Task Modes
The AI workspace gives testers two ways to work. Chat mode is built for quick conversational iteration, like asking it to "generate 50 sample customers and show me the output." Task mode is built for goal-driven multi-step work that runs on a worker pool, streams progress back to the user, and produces concrete deliverables such as CSV bundles, generated templates, and scenario scripts.
Users can attach images, PDFs, JSON files, single CSVs, or entire CSV folders. The CSV-folder workflow in particular can analyse multiple related files together, infer the structure and relationships across them, and build reusable templates and synthetic outputs in one move. This compresses what was traditionally days of manual schema modelling into a single chat session.
d. Retrieve Real Data from SAP and Connected Systems
Alongside synthetic generation, DataMaker can fetch real records from any connected system, whether that's SAP via OData, REST APIs, or supported databases. Testers describe what they want in plain English, the AI applies the appropriate filters, and the records come back as a typed table that can be saved as a reusable dataset.
This is especially valuable for building realistic regression sets, reproducing production defects in QA, or seeding sandbox environments with carefully filtered slices of real data.
e. Scriptable Data Workflows (Scenarios) with CI/CD Triggers
DataMaker includes a built-in Python scripting workspace called Scenarios, where teams can author multi-step data workflows. A typical Scenario might generate customers, generate orders that reference those customers, post them to SAP, verify the result, and write a report.
Scenarios run on DataMaker's worker pool with configurable timeouts (1 to 60 minutes), live log streaming, environment variables for secrets, and per-project organisation. Crucially, they can be triggered from outside DataMaker via REST API with an authenticated key. That's what makes them work natively inside GitHub Actions, GitLab CI, Jenkins, CircleCI, and similar pipelines.
f. Extensible AI Capabilities via MCP Servers
DataMaker uses MCP (Model Context Protocol) servers to give the AI workspace access to real product capabilities. The core DataMaker MCP ships with 25+ tools covering data generation, template management, connections, scenarios, and data export.
An optional DataMaker SAP MCP adds a specialised toolkit for SAP-oriented workflows, including metadata operations, filtered retrieval, and SAP-specific export flows. Teams can enable additional capabilities per workspace depending on their environment, without changing tools.
g. Connect DataMaker to External AI Coding Assistants
DataMaker also exposes its own MCP server that developers can connect to MCP-compatible AI assistants such as Claude, Cursor, and GitHub Copilot using their DataMaker credentials. Once connected, the developer's existing assistant can invoke DataMaker workflows directly from the editor or chat environment.
That includes generating data, retrieving records, and delivering data to target systems. The result is that DataMaker fits into the modern AI-augmented development workflow, rather than test data being treated as a separate, manual step.
Pros
- Hybrid synthetic generation and real-data retrieval from SAP and connected systems
- AI-assisted onboarding with two modes (Chat and Task) and rich file analysis covering images, PDFs, JSON, single CSVs, and CSV folders
- Native OData integration with metadata discovery, filtered retrieval, and automatic CSRF handling
- Multi-database support (PostgreSQL, MySQL, MongoDB, MSSQL, Oracle, IBM DB2) plus REST API delivery
- CI/CD-native via REST-triggerable Python Scenarios with log streaming and configurable runtimes
- MCP integration with AI coding assistants like Claude, Cursor, and GitHub Copilot
- Reusable, sharable templates with 50+ built-in data types, statistical distributions, and custom logic
- Privacy-by-design synthetic data, reducing GDPR and compliance exposure
Cons
- Not a full enterprise Test Data Management suite
- Focused on test-data workflows rather than in-place anonymisation of production estates
- Not designed for full system-copy or landscape-cloning scenarios
Pricing
Custom pricing. Enterprise-oriented. Contact sales for pricing.
Verdict
DataMaker is a strong choice for SAP QA teams that want clean, synthetic test data they can control without relying on production copies or heavyweight enterprise TDM systems. It's also increasingly relevant for teams whose work spans CI/CD pipelines, privacy-sensitive environments, and AI-assisted development workflows.
With template-based modelling, dual-mode AI workflows, real-data retrieval from SAP, scriptable Python Scenarios, and MCP integration with both internal and external AI assistants, the platform helps teams prepare consistent datasets for automation, regression testing, and continuous delivery.
Its OData-native SAP integration, with metadata discovery and automatic CSRF handling, makes it particularly easy to plug into S/4HANA and RISE with SAP environments.
If you're considering modernising away from SAP TDMS, or simply want a faster, AI-driven path to realistic SAP test data, DataMaker is a highly practical solution worth evaluating.
To see how this works in practice, explore this step-by-step guide on generating SAP test data with DataMaker.
2. GenRocket
GenRocket is an enterprise synthetic test data automation platform designed for teams that need high-volume, configurable, and privacy-safe data for ERP environments such as SAP S/4HANA.
It uses a design-driven approach where testers model domains, rules, and workflows, and the platform generates synthetic scenarios that reflect business logic, patterns, and distributions without relying on production data.
GenRocket can also blend masked subsets with synthetics, which helps organizations transition gradually away from production-based testing.
It integrates through REST APIs, JDBC (for HANA), and CSV templates, making it suitable for SAP teams that need real-time data provisioning for functional, integration, regression, and performance tests. While not SAP-exclusive, its architecture fits large, regulated enterprises seeking scalable test-data automation.
Top 5 Features
a. Design-Driven Synthetic Data Modeling
GenRocket uses a design-driven approach where testers model domains, rules, and data relationships before generating datasets. This allows teams to create synthetic data that reflects real business logic and workflows while maintaining referential integrity across complex datasets.
b. Hybrid Synthetic and Masked Data Strategy
The platform supports both fully synthetic data generation and masked subsets of production data. This allows organizations to adopt synthetic testing gradually while preserving certain production patterns when needed.
c. Real-Time Test Data Provisioning
GenRocket can generate and deliver test data on demand through REST APIs, JDBC connections, or file templates. This allows automated test suites and CI/CD pipelines to request fresh datasets during execution instead of relying on static data.
d. High-Volume Data Generation
The platform is designed for enterprise environments that require large datasets for load, regression, and edge-case testing. It can generate millions of records quickly while maintaining the relationships and rules defined in the data models.
e. Enterprise Test Data Management Controls
GenRocket provides governance features such as role-based access control, versioned test data scenarios, and audit tracking. These capabilities help large QA teams manage test data workflows across complex enterprise environments.
Pros
- Strong synthetic data capabilities that avoid production data exposure
- Highly flexible and supports SAP-aligned domain modeling
- Scales well for large, complex enterprise test scenarios
- Integrates with DevOps pipelines and automation frameworks
- Can dramatically reduce provisioning time compared to copying SAP data
Cons
- Steeper learning curve for domain modeling and initial setup
- Not as SAP-specific as tools like Broadcom TDM or DSM
- Pricing may be challenging for small teams Requires accurate design modeling; poor models produce poor data
- Limited volume of SAP-specific user reviews
Pricing
Enterprise pricing only. No public tier or per-user pricing available.
Verdict
GenRocket is a strong choice for SAP teams that want scalable, synthetic test-data automation without depending on production copies. Its design-driven approach delivers flexibility and depth, especially for complex enterprise workflows that require high-volume or real-time test data.
However, teams with deep SAP-specific requirements may need to supplement GenRocket with more SAP-focused tools or invest time in modeling to achieve optimal results.
3. EPI-USE Labs Data Sync Manager (DSM)

Data Sync Manager (DSM) is an SAP-certified test data provisioning suite designed to help teams build realistic, compliant, and manageable SAP test environments.
Instead of full system copies, DSM focuses on selective copying, subsetting, and masking of production data, allowing organizations to create smaller and more efficient QA systems while maintaining functional integrity.
Its core components, including Client Sync, Object Sync, and Data Secure, enable teams to refresh SAP clients, extract specific business objects, and anonymize sensitive data using pattern-breaking techniques. DSM supports S/4HANA, RISE with SAP, and hybrid landscapes, helping reduce post-copy steps and minimizing overall landscape complexity.
DSM is a strong fit for organizations that need accurate, privacy-safe, and production-aligned test data while working within agile delivery cycles or migrating to cloud-centric SAP architectures.
Top 5 DSM Features
a. Client Sync for Selective Client Refreshes
Enables full or partial client refreshes using filters such as date ranges, organizational units, or functional slices. This keeps QA systems aligned with production while avoiding the storage and downtime impact of full system copies.
b. Object Sync for Granular Business Object Copying
Allows teams to copy specific SAP business objects, including HCM master data, payroll clusters, sales orders, and financial documents, while automatically preserving relationships and dependencies. Ideal for targeted testing, training, or defect reproduction.
c. Data Secure Masking Engine
Provides irreversible, rule-based anonymization across more than 1,300 SAP fields. Sensitive information remains functional for testing but fully anonymized for compliance with GDPR, HIPAA, and other global privacy standards.
d. Time-Slice and Subsetting for Lean Test Environments
Extracts only the necessary portions of production data, such as a 6-month slice or specific plants/regions. This reduces system size, improves performance, and accelerates provisioning of new test clients.
e. SAP-Certified Integration with Reduced Post-Copy Effort
Certified for SAP S/4HANA and RISE with SAP, DSM reduces the need for heavy post-copy steps like BDLS, lowering operational overhead and simplifying landscape management for Basis and QA teams.
Pros
- Intuitive SAP-like interface for defining what to copy
- Strong compliance capabilities with built-in masking and anonymization
- Helps reduce infrastructure cost through smaller test landscapes
- Familiar UI enhances adoption among SAP teams
- Suitable for broad SAP modules, including complex HCM and Payroll scenarios
Cons
- Focused on copying and masking production data; not suitable for synthetic data generation
- Setup and maintenance may require SAP/Basis expertise
- Higher learning curve for teams without prior TDM experience
Pricing
Custom enterprise pricing. Typically sold as part of SAP landscape optimization or test data management services.
Verdict
Data Sync Manager is an excellent choice for enterprises that need realistic, compliant, and regularly refreshed SAP test environments. It excels in reducing system footprint, speeding up test-client refreshes, and preserving business integrity across modules.
However, teams needing fully synthetic SAP test data or edge-case scenarios not present in production will need to pair DSM with a synthetic-first solution.
4. K2View Test Data Fabric
K2View Test Data Fabric is an enterprise-grade test data management platform built to deliver complete, compliant, and on-demand test data across SAP and non-SAP systems.
Unlike traditional approaches that rely on system-level copies, K2View organizes information into “micro-databases,” each containing all data related to a specific business entity such as a customer, order, or supplier. This architecture enables fast extraction, masking, subsetting, and delivery of test data at scale.
K2View also includes a synthetic data generation engine that allows teams to create entirely new, realistic datasets when production data is incomplete or cannot be used for compliance reasons. This makes it a hybrid solution, combining subsetting, masking, and synthetic generation in one platform, and supporting both SAP and distributed enterprise landscapes.
Top K2View Data Fabric Features
a. Micro-Database Architecture
Bundles all related records for a business entity into a secure micro-database, enabling rapid extraction and delivery of complete, consistent datasets without running full system copies.
b. Synthetic Data Generation Engine
Generates realistic, privacy-safe synthetic data using rules, patterns, AI-based generation, and entity-modeling techniques. Useful when teams need fresh data or want to avoid production dependencies.
c. Advanced Data Masking and Tokenization
Provides deterministic masking, tokenization, and anonymization options to ensure compliance across development, QA, staging, and training environments.
d. Intelligent Data Subsetting
Allows selective extraction of only the necessary slices of SAP data, reducing system size and improving environment performance while maintaining referential integrity.
e. Real-Time Data Provisioning and CI/CD Integration
Supports self-service portals, APIs, and CI/CD pipelines to provision fresh test data on demand, ensuring that automation teams always have the right data at the right time.
Pros
- Combines masking, subsetting, and synthetic data generation
- Very fast data provisioning using micro-database technology
- Strong compliance features with advanced anonymization
- Ideal for multi-system landscapes that include SAP, CRM, billing, and data warehouses
- Good integration with CI/CD workflows and automation pipelines
Cons
- Complex to implement for smaller teams or simple SAP landscapes
- Heavy enterprise platform, more suited for large organizations
- Focuses broadly on enterprise test data, not SAP-specific generation patterns
- Requires specialized data engineering or platform expertise
Pricing
Enterprise-level custom pricing. Typically licensed as a data platform with optional implementation and consulting services.
Verdict
K2View is a strong choice for large organizations that need fast, compliant, and multi-system test data provisioning with the flexibility to generate synthetic data when needed. Its hybrid approach makes it powerful in complex SAP environments, especially when data must span multiple systems.
However, for teams looking for lightweight, SAP-specific synthetic test data generation or simple QA workflows, K2View may be more platform-heavy than necessary.
5. Delphix Test Data Management for SAP
Delphix Test Data Management (now part of Perforce) focuses on delivering compliant, production-like test data using its core strengths: data virtualization, automated masking, and rapid environment provisioning.
Instead of creating full database copies, Delphix captures a compressed, virtualized copy of SAP data sources such as HANA or Oracle, applies masking rules to protect sensitive information, and provisions lightweight virtual datasets to developers and testers.
This approach reduces storage consumption and accelerates non-production refresh cycles, making it suitable for SAP teams that need frequent, reliable, and compliant data access.
While Delphix is strong in virtualization and masking, it does not specialize in SAP-specific object relationships or native subsetting, so extremely complex landscapes may require additional tooling or configuration.
Top 5 Delphix SAP TDM Features
a. Virtualized Data Copies Creates and provisions virtual SAP datasets in minutes, removing the need for full system copies and cutting storage usage dramatically.
b. Automated Data Masking Built-in sensitive data discovery and masking capabilities, including deterministic masking, help maintain compliance across SAP modules like HR and finance.
c. Fast Refresh, Rewind, and Branching Enables rapid refresh and rollback operations, supporting CI/CD pipelines and iterative SAP development cycles.
d. Cloud and DevOps Integration Works with Azure Data Factory, pipelines, automation frameworks, and cloud platforms to streamline SAP data delivery.
e. Centralized Data Library Versioning, cataloging, and access controls enable teams to manage multiple SAP datasets securely and consistently across non-production environments.
Pros
- Extremely fast virtual provisioning (minutes rather than hours or days)
- Strong masking and compliance features for regulated industries
- Major storage savings due to virtualization
- Good integration with DevOps workflows and cloud automation
- Helpful for maintaining fresh, production-aligned data without cloning full systems
Cons
- Subsetting can struggle with complex SAP referential integrity, leading to inconsistencies in highly interconnected environments
- Performance slows on very large, multi-terabyte SAP datasets
- No dedicated NoSQL or modern unstructured data connectors
- Older UI and configuration steps may require experienced administrators
- Limited synthetic data features compared to newer AI-driven platforms
Pricing
Enterprise-level pricing. Not publicly listed; often packaged as part of broader TDM or data platform contracts.
Verdict
Delphix is a strong option for SAP teams that prioritize fast, compliant, and storage-efficient test-data provisioning. Its virtualization and masking capabilities make it ideal for organizations that need frequent refreshes and secure, production-like data without creating full system copies.
However, SAP environments with extremely complex relationships or advanced synthetic data requirements may need complementary solutions. For most mid-sized to large SAP landscapes, Delphix delivers significant speed and compliance benefits, especially in DevOps and cloud-centric pipelines.
How to Choose a Third-Party SAP Test Data Solution
| Scenario | Best Type of Tool | Why Third-Party Tools Are Needed |
| You need stable, repeatable data for automation | Synthetic generators (e.g., DataMaker, GenRocket) | Automation requires fresh data that doesn’t get consumed. |
| You want compliant data without using production records | Synthetic-first tools | Full elimination of PII. Better GDPR alignment. |
| Your CI/CD pipeline needs on-demand data | API-driven generators (DataMaker), or orchestration platforms (K2View, Delphix) | Native tools cannot deliver data instantly or repeatedly. |
| You must test edge cases not found in production | Synthetic data generators (e.g., DataMaker, GenRocket) | Production data rarely includes exceptions or error conditions. |
| Your processes span SAP + CRM + custom apps | Enterprise TDM platforms (K2View, Delphix) | Ensures cross-system consistency for end-to-end flows. |
| You want to avoid heavy system copies or refreshes | Synthetic tools or subsetting platforms (DataMaker) | Lighter, faster, and automation-friendly compared to full client copies. |
Third-party SAP test data tools offer flexibility, scalability, and automation-ready data that native tools cannot deliver. They are ideal for teams operating in fast-paced environments, running CI/CD pipelines, or requiring synthetic and edge-case data that goes beyond what production systems can provide.
Final Words
Choosing the right SAP test data generation approach depends entirely on your use case. Native SAP tools work well for basic setups and production-aligned testing, but they reach their limits when automation, compliance, or complex scenarios come into play.
Third-party test data solutions fill this gap by offering synthetic data, on-demand provisioning, and cross-module consistency.
By understanding your testing needs and selecting the right tool, you can improve test coverage, reduce environment issues, and enable faster, more reliable SAP delivery cycles.